


Жив, жив курилка
Но все эти месяцы — да уже и годы — по-прежнему каждый день собирались и обсчитывались данные, каждый день работали асессоры, каждый день публиковались свежие результаты по всем 43 опубликованным анализаторам. В чём легко убедиться, просто открыв в любом из анализаторов график «все» (за всё время сбора данных).
А еще регулярно обновлялись маркеры во многих анализаторах.
А еще мы планируем опубликовать пару совершенно новых анализаторов.
А еще с осени 2014 года мы параллельно работаем над новым проектом — тоже анализаторами, но совсем другими. Наши SEO-анализаторы показывают, какие факторы ранжирования могут учитываться поисковыми машинами. См. о них в презентациях наших докладов на конференциях «Поисковый маркетинг и продвижение бизнеса в интернете»: Черные ящики говорят и показывают, 2015 и Мониторинг факторов ранжирования Яндекса и Google: что нового в 2016.
Изменения в ранжировании Яндекса
В то же время, изменения оказались пусть и заметными, но никак не глобальными. Результат анализатора 13 марта — 20%. Такие же результаты анализатор показывает раз в 2-3 недели. Основное отличие в том, что обновление коснулось выдачи не по всем запросам (основной анализатор апдейтов показал только 9%, тогда как до сих пор результаты анализаторов различались максимум на 2-3 пункта) и не во всех регионах.
Такие мягкие последствия перехода на новую формулу ранжирования показывают, что Яндекс долго и тщательно готовился к нововведениям, постепенно увеличивая вес других факторов при формировании выдачи. Масштабных изменений в выдаче не планировалось, мы их и не увидели.
Ограниченность изменений может объясняться и грамотными действиями оптимизаторов. О готовящемся отказе от ссылок было объявлено больше трёх месяцев назад; за это время акцент мог сместиться в сторону нессылочных методик продвижения.
Мы продолжим наблюдать за результатами анализатора Коммерческих апдейтов, в первую очередь — в регионах, где от ссылочного фактора пока не отказались.
Новый анализатор: коммерческие апдейты
«С начала 2014 года, для начала — для коммерческих запросов по Москве — ранжирование будет вообще не учитывать ссылки», — таким сенсационным сообщением завершил свой доклад на конференции IBC Russia 2013 руководитель поисковых сервисов Яндекса Александр Садовский. «Качество поиска остаётся не хуже», — добавил он.
Мы решили посмотреть, насколько изменятся результаты поиска после этого нововведения и сделали анализатор, аналогичный анализатору апдейтов, но со специально подобранными коммерческими запросами — по которым, насколько мы можем судить, активно идет «ссылочное» поисковое продвижение. В новом анализаторе можно отслеживать, насколько сильно меняется выдача Яндекса по этим запросам в Москве — и сравнивать изменения с аналогичными в других регионах. Кроме того, можно оценить «накопленные» изменения в выдаче за период в 30 дней.
За первые два месяца работы анализатора никаких скачков, не совпадающих по времени со скачками в основном анализаторе апдейтов, замечено не было. Изменения выдачи в регионах также практически не отличаются от синхронных им изменений в Москве. Судя по всему, пока ничего интересного не произошло. По последним данным, Яндекс теперь обещает ввести новый, «бессылочный» алгоритм в марте...
SEO-прессинг - закрытие анализатора
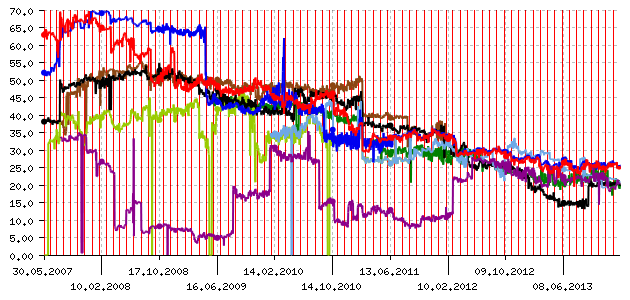
Анализатор показывает долю активно продвигаемых коммерческих сайтов специфической «узкой» направленности в выдаче по «широким» запросам, обычно не имеющим однозначно коммерческого смысла. Когда таких сайтов в результатах поиска становится слишком много, — например, если по запросу [вода] выдаются только (или почти только) сайты про доставку питьевой воды в офис, — можно констатировать, что поисковая машина поддается SEO-прессингу.
Легко видеть, что несколько лет назад у всех ведущих поисковиков от 50 до 70% выдачи по общим коммерчески значимым запросам составляли сайты, предлагавшие вполне конкретные товары или услуги. Эта ситуация, конечно, была достаточно неприятной: у запроса могут быть разные «цели», а выдача должна отвечать как можно большему их количеству. В то же время, 2-3 коммерческих сайта в выдаче должны присутствовать, ведь вполне вероятно, что пользователя, задавшего запрос [Тайланд], интересуют туры в Таиланд, а задавшего запрос [электростанция] — электростанции для загородного дома.
Основное назначение анализаторов — помогать разработчикам видеть (и устранять) слабости своих машин, а заинтересованным наблюдателям — сравнивать имеющиеся технологии. Анализатор SEO-прессинга просуществовал более шести лет, и теперь мы можем констатировать: за это время ведущие поисковики проделали путь от 50-60% до 20-30% коммерческих результатов в выдаче по запросам анализатора, т.е. достигли оптимальной их доли. В то же время, в этом диапазоне разница между поисковиками выглядит несущественной, да и определённо сказать, что «чем меньше, тем лучше», — трудно. Так что нам остаётся лишь с радостью заметить, что по крайней мере этот анализатор свою миссию выполнил, и его дальнейшее существование малоинтересно.
Как всегда, результаты анализатора за любой день доступны на его странице, однако запуски с марта 2014 года прекращаются. Соответственно, анализатор больше не будет учитываться для вычисления интегрального показателя качества поиска и показателя разнообразия результатов поиска.
Новые запросы в анализаторе актуальности должностей
Мы регулярно обновляем маркеры (запросы и правильные ответы) в анализаторе актуальности должностей. Такие замены обычно происходят постепенно — иногда 4 запроса, иногда 27 (ср. сегодняшние, 11.12.2013, изменения в анализаторе актуальности телефонов). Но время от времени мы собираем сразу полный комплект маркеров и заменяем их все единоразово. В такие моменты особенно интересно сесть в позу лотоса и наблюдать за изменениями в результатах поисковых машин.
Каждое обновление запросов в анализаторах актуальности вызывает снижение результатов, что неудивительно: "новые назначения" из старых маркеров давно уже "дошли" до множества сайтов, и находить достоверную информацию уже не так сложно. Новые же запросы связаны с изменениями, произошедшими совсем недавно, и выбрать страницы, где это отражено, не слишком просто. Примеры падений результатов всех или большей части поисковиков можно видеть на графике анализатора в конце сентября 2011 и в середине мая 2012.
В этот раз ситуация выглядит несколько по-другому: нельзя не отметить катастрофическое падение результатов Mail.ru, с близких к лидерам 75 процентов до рекордно низких 26. На фоне падения Google и Яндекса на привычные 5 и 9 пунктов соответственно, этот обвал удивителен.
Новые анализаторы: запросы с числами
Числа могут встретиться в запросах самого разного содержания — от номера модели до названия произведения искусства. И если запрос 1984 почти наверняка будет понят поисковиком правильно, то узнать, кто играет в Динамо под 16-м номером — практически невозможно даже в лучших поисковых машинах: в том, что касается содержащегося в нем числа, запрос будет, скорее всего, проинтерпретирован весьма вольно.
Запросы анализатора моделей — не самые распространённые, но встречающиеся (как в жизни, так и в интернете) модели техники, иногда с указанием, какой именно, иногда без. Проверяется, что нужная модель найдена: учитываются другие названия или коды той же модели, но не учитываются похожие и аналогичные), всё остальное считается ошибкой. Здесь результаты предсказуемо достаточно высокие, несмотря на относительную редкость моделей. Всё же запрос однозначно связывает числовой индекс с предметом, да и в интернете обычно сам текст запроса в неизменном виде представлен достаточно широко. Вот и результаты — заметно за 80%, т. е. как минимум 8 из 10 результатов — про нужные модели.
Заметно хуже обстоят дела с «числовым» анализатором: он задаёт «немодельные» запросы, содержащие числа, причём значения этих чисел самые разнообразные: номера, технические характеристики, части названий и пр. Как это нередко бывает, запросы разделились на простые и сложные, это хорошо заметно по яркости соответствующей полоски в таблице результатов. «Наименования» (названия песен, коды документов и т. п.) ищутся заметно лучше менее привязанных к тексту «номеров» (например, глав или серий) и требуемых «свойств» (объёмов, мощностей и т. п.). Результаты анализатора — доля ответов, где поисковик интерпретировал запрос в соответствии с его смыслом.
Увы, по крайней мере один из трёх или четырёх ответов оказывается совсем не по делу. Зато иногда получается довольно смешно.
Новый анализатор: поиск адресов
Анализатор поиска адресов, или «Business locations», моделирует ситуацию, с которой каждый из нас сталкивается регулярно, когда ему нужно — обычно перед выходом в офлайн — найти отделение банка (БТИ, кафе, поликлинику и т. п.). Обычно в таких случаях мы указываем тип организации, которую ищем, и ориентир — улицу, район, станцию метро.
Для анализатора выбраны описания такого типа, под которые подходит ровно один объект. Мы проверяем, насколько хорошо поисковым машинам удаётся найти искомую организацию и на каком месте в результатах поиска пользователь увидит её адрес.
При этом приходится учитывать не только собственно результаты поиска, но и различные элементы «расширенной выдачи» — прежде всего, блок карт, который есть теперь у всех ведущих поисковых машин, и который может дать лучший ответ на вопрос о том, где находится искомое заведение.
К сожалению, идеальный ответ пользователь получает далеко не всегда; нередко нужный адрес приходится выискивать далеко за границей «первого экрана». Однако ситуации, когда адреса вообще нет на странице выдачи, случаются крайне редко — что не может не радовать.
Разделение транзакционного анализатора
Анализатор официальных версий был создан как первый из транзакционных – он проверяет, что поисковики предлагают скачать то, что можно скачать легально, именно на официальных страницах. Однако с момента публикации стало понятно, что официальные версии программного обеспечения находятся гораздо лучше, чем сайты музыкальных групп, киностудий и других производителей «контента». Мы решили разделить анализатор на два – так они оба будут более однородными, не смешивая разные, как оказалось, вещи в одну.
Подбор дополнительных маркеров занял значительное время, но теперь оба анализатора существуют независимо. При этом каждый из них сохранил свою часть запросов из смешанного анализатора, за исключением утративших свою актуальность. Различие в результатах служит отличной иллюстрацией того, что разделение было вполне оправдано.
Новый анализатор: грамматика
Мы решили посмотреть, сколько таких ошибок делают разные поисковики — и вот публикуем грамматический анализатор. Он стал уже пятым в группе анализаторов ошибок.
Ошибки возникают, например, когда парадигмы двух разных слов пересекаются. У слов кружок и кружка есть общая (с точностью до ударения) форма: кружки. Немного воображения — и по запросу кружок керамики начинают находиться керамические кружки.
Еще один типичный случай — когда поисковик начинает склонять несклоняемое слово. Вирус куру — это не вирус кур, но ошибиться так легко!
Особенно неприятно (для поисковых машин, а следовательно, и для их пользователей), когда в запросе встречается форма, имеющаяся одновременно у двух совершенно разных слов. Например, знать может быть и глаголом, и существительным, — и тут, чтобы ошибиться, вообще ничего менять не требуется: достаточно по запросу испанская знать показать что нужно знать, отправляясь в Испанию.
Иногда поисковик мог бы избежать ошибки, обратив внимание на то, что одно из слов запроса почему-то употреблено не в начальной форме. Возможно, это вообще другое слово — ср., запрос группа компаний РуссКом, по которому находится группа компаний Русский алкоголь. А может быть, это название или цитата, и лучше это зря не склонять — ср. стихотворение Собаке Качалова и рок-группу Собаки Качалова.
Как и в любом анализаторе ошибок, худший результат в этом анализаторе может быть платой за то, что поисковая машина сильнее в чём-то другом — например, что она умеет склонять редкие, незнакомые, «несловарные» слова. Мы постараемся рано или поздно сделать анализаторы, которые будут оценивать положительный эффект от такого рода умений. Пока исследуем отрицательный — это ведь, понятное дело, проще.
Надеемся, что анализатор поможет разработчикам поисковых машин решить проблемы, которые он высвечивает. Повод для оптимизма есть: уже за время разработки анализатора некоторые ошибки пропали. Видимо, чем дальше, тем сложнее будет придумывать «трудные» запросы. Что ж — чем тяжелее нам, тем лучше пользователям.
Изменения в сводных показателях
С 1 февраля изменена формула расчёта интегрального показателя качества поиска и сводных показателей отдельных групп. Результатом стал заметный скачок всех поисковиков на графиках этих показателей, причём, если рост лидеров был весьма умеренным, «отстающие» подскочили очень значительно. Что же это означает?
Всё дело в методе подсчёта. До 01.02.2013 мы использовали формулу, присваивавшую в каждом анализаторе поисковикам значения от 0 (худшему) до 100 (лучшему), промежуточные же результаты пересчитывались в стобалльные пропорционально. Таким образом, худший в конкретном анализаторе поисковик получал за него оценку 0, даже если на деле его результат отличался от лидера всего на несколько процентов. Например, результаты 80, 50 и 40 были бы пересчитаны в 100, 25 и 0.
Этот метод подсчёта хорош, когда все результаты идут очень плотной группой – чтобы подчеркнуть разницу. Но когда разброс в отдельных анализаторах превышает 50% результата лидера (например, здесь), он перестаёт быть эффективным. Зато создаётся ощущение, что худшие поисковики не умеют совсем ничего (см. график, до 1 февраля), что, конечно, не соответствует действительности. К тому же, для «худших» характерны заметные скачки, которые при старой формуле обеспечивают «пилу» на графиках у всех остальных (см. график: до и после 1 февраля), что тоже достаточно странно.
Оценив плюсы и минусы, мы решили отказаться от нижней границы шкалы – теперь при подсчёте сводных показателей результат лучшего в анализаторе поисковика принимается за 100 баллов, а остальные считаются пропорционально. То есть для случая из примера выше (результаты трёх поисковиков 80, 50 и 40), при пересчёте в стобалльную систему мы получим 100, 61,5 и 50.
Кроме того, с 1 февраля мы поменяли местами результаты асессорского анализатора и значения сводного показателя на главной странице проекта. Несмотря на то, что при вычислении последнего используется гораздо больше факторов, нам кажется, что ручная оценка релевантности и качества страниц по набору довольно разнообразных запросов лучше отражает качество поиска с точки зрения пользователя – поэтому его удобнее видеть первым.
Персонализация?
Новость подхватили журналисты множества изданий, запестрели заголовки вроде «Яндекс» сделал поиск персональным (Slon.ru) или Поиск по вкусу. «Яндекс» запустила новую поисковую систему, которая будет лучше понимать желания пользователя (Газета.ru). В пресс-релизе Яндекса менеджер проектов Денис Рогачевский утверждает, что персонализация «позволяет улучшить качество ответов примерно на 75-80% запросов пользователя», — правда, в комментарии Roem.ru он же признается, что не всякого: «это около 60% всех запросов к Яндексу».
Так что же теперь будет? Чего ждать? Неужели меня действительно сосчитали, и теперь Яндекс будет всегда выдавать мне то, что я ищу, основываясь на «всей истории» моего «поведения»? Действительно ли поисковая оптимизация стала бессмысленной, а наши анализаторы — бесполезными, раз уж сами разработчики Яндекса советуют теперь вместо ссылок на результаты поиска обмениваться скриншотами?
Давайте попробуем понять, что произошло, основываясь на том, что сказано на сайте самого Яндекса — в описании технологии и на специальной странице с примерами personalization.yandex.ru.
Если им верить, то речь идет о довольно узкой группе запросов — о тех, которые допускают двоякое (или больше) «прочтение». (Вероятно, как-то персонализируются и другие запросы, но сайт Яндекса об этом умалчивает.) Например, кино — это или кинематограф, или рок-группа, и пользователь в принципе мог иметь в виду как то, так и другое. Таких запросов на самом деле относительно немного, никак не 75% и даже не 60%, хотя они и могут быть частотными. Почти любое уточнение неоднозначность убирает.
Да и в этом случае речь идет скорее о перегруппировке (переранжировании) ответов, чем о замене одних ответов другими. Всё равно на неоднозначные запросы любому пользователю придется давать разнообразные ответы (см. наш анализатор омонимов)! Не случайно в примере Яндекса меломану Юре в ответ на запрос Бетховен уже на четвертом месте выдается Кинопоиск.Ру, а киноведу Никите — Людвиг ван Бетховен. (Выдача для киноведа по этому запросу, кстати, — хороший пример того, как персонализация может выйти боком — всё-таки даже киноведу на первой позиции, наверное, лучше было бы показать настоящего Бетховена, а потом уже фильмы про одноименную собаку.)
Поэтому опасения, высказываемые в Сети, представляются преждевременными.
Правда ли, что разным пользователям будут показаны разные пластиковые окна, — и это смешает карты и самим оптимизаторам, и их клиентам? — Вроде бы, об этом речь пока совершенно не идет.
Не получится ли так, что малолетний сын, поискав игрушки в Яндексе отца, найдет совсем не те игрушки? — Нет, не найдет: с неоднозначными запросами, имеющими эротическую интерпретацию, Яндекс научился работать давно и хорошо, и вряд ли «Калининград» тут что-либо изменит.
Не останутся ли наши анализаторы поисковых машин не у дел? — Не останутся. Доля запросов, для которых что-то изменится, невелика, да и по ним персонализация — только дополнительный фактор ранжирования, не отменяющий всех остальных.
Яндекс учится более тонко учитывать запросы, поведение пользователей, тематику сайтов и страниц и тому подобные тонкие материи. Это очень непростая и в принципе весьма полезная работа. Однако попытки применить подобные тонкие лингвистические (или, точнее, статистические) технологии на практике неизбежно приводят не только к улучшению работы поиска в некоторых случаях, но и к ухудшению — в других. Этому посвящены наши анализаторы «глупостей».
Нисколько не сомневаюсь, что «глупости» будут и на этот раз. Даже в собственных примерах Яндекса, доступных по ссылкам с personalization.yandex.ru, их уже хватает. Упомянутый выше любитель Бетховена меломан Юра на запрос ария получает 10 ответов про группу «Ария» и ни одного — про оперные арии (видимо, он так хорошо в них разбирается, что дополнительные ответы от Яндекса на столь общий вопрос ему уже не нужны). А по запросу кино, заданному от имени меломана Юры, Яндекс отвечает, что «меломан Юра таких вопросов не задает», и выдает все ответы про фильмы — ровно те же, что и киноведу Никите.
Пока не видно, как сделать анализатор, который оценивал бы качество персонализации, но мы уже начали об этом думать.
Новая серия анализаторов: неожиданные ошибки
Мы готовили их довольно долго, зато теперь публикуем сразу четыре. И впереди ещё несколько.
Если смотреть исключительно на эти анализаторы, может возникнуть ощущение, что поисковики просто издеваются над пользователями. Однако это совсем не так. Мы долго и тщательно подбирали запросы для каждого из этих анализаторов, чтобы показать, к каким ошибкам могут приводить действия поисковиков по улучшению запроса. Но такие действия отнюдь не бессмысленны – достаточно посмотреть на результаты анализаторов «понимания запроса».
В некотором смысле, ошибки – это оборотная сторона того достаточно качественного поведения, которое демонстрируют поисковики в ситуациях, где запрос явно нуждается в правке. Например, легко ли обойтись без неоправданных замен запроса поисковику, которы добивается высочайших, около 95%, результатов в анализаторе исправления опечаток? Другие ошибки также связаны с тем, что во многих ситуациях аналогичное поведение приводит к улучшению запроса – и результатов.
Впрочем, для человека, который ищет информацию о писателе Павле Чацком, а находит сплошное «Горе от ума», всё это будет слабым утешением. Так что разработчикам поисковых машин, хочешь–не хочешь, придется решать проблемы, которые нашли – или ещё найдут – своё отражение в анализаторах этой серии.
Опубликован тридцатый анализатор
Навигационный анализатор был одним из первых в AnalyzeThis. Его статистика доступна с 2007 года, и тогда показатели поисковых машин по этому параметру составляли от 30 до 90%. С тех пор поисковые машины — причем все, включая и аутсайдеров — научились справляться с запросами этого анализатора почти на 100%. Теперь 98% или даже 99% «попаданий» у Яндекса или Гугла — чаще результат «сгорания» маркера, чем ошибка поисковой машины. И даже при таком способе подсчета, когда учитывается не только наличие нужного результата в десятке, но и его позиция, результат 100% стал уже вполне обычным.
Поэтому мы решили проверить — что будет, если усложнить поисковикам задачу. Если заставить их искать не министерство, а колхоз, не крупную московскую корпорацию, а техникум в Тьмутаракани.
Мы специально старались подобрать запросы потруднее — и всё равно нередко оказывалось, что с ними справляются все поисковые машины. Мы перебирали в поисках нетривиальных маркеров города районного масштаба: Кашин, Калязин, Судогда, ... В конце концов мы даже отказались от идеи, что годятся только такие запросы, которые хотя бы для кого-то оказались не по зубам.
И вот итог. Даже в таких нечеловеческих условиях поисковики оказались на высоте! И 90% «попаданий» у лучшего, и даже 75% у худшего — это очень высокие показатели. Можно с удовольствием констатировать: поисковые машины добились в навигационном поиске выдающихся результатов.
Поздравляем!
И еще один итог, уже наш собственный. С публикацией «периферийного навигационного» количество анализаторов достигло 30. Три «линейки» по 10 анализаторов заполнены. Дальше расширяться некуда. Делаем новый сайт!


